A Walkthrough on Image Segmentation using a U-Net Framework

Delving into the transformative world of image processing, this article lays a strong foundation on the fascinating concept of image segmentation using U-Net. In the realms of computer vision, image segmentation has etched out a significant niche, empowering machines to unravel the complexities of visual data. The bedrock of this metier is the U-Net Framework, a pioneering structure uniquely engineered to elevate the process of image segmentation. Residing at intersections of innovation and application, the U-Net Framework plays a pivotal role in an array of industries, helping decode an expanding universe of visual data. By fathoming the nuances of U-Net Framework, we embark on a journey of deciphering the intricate layers of the U-Net architecture, and how they ably process input images, thereby contributing to building robust U-Net models. Buckle up as we set sail on this captivating voyage of image segmentation, exploring the intricacies of the U-Net Framework and understanding the profound impact in the realm of visual data interpretation.
What is U-Net Framework?
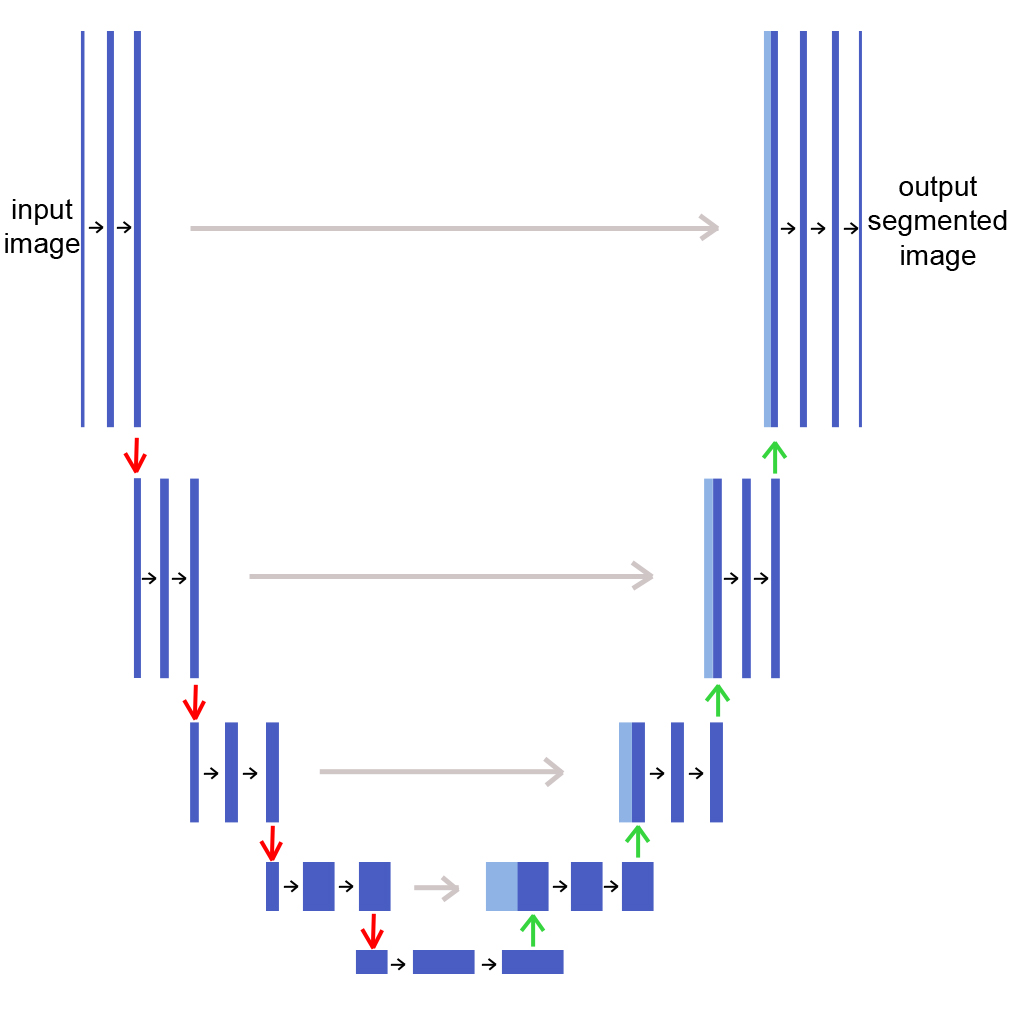
The U-Net Framework serves as a vital architecture focusing specifically on biomedical image segmentation topics. As a Convolutional Neural Network (CNN), its structure leverages powerful and precise image processing abilities, making it particularly suited to the high-resolution demands and heavily detailed requirements of medical imaging. The U-Net naming derives from its U-shaped architecture, a design that is not common within the realm of CNNs.

One of the primary applications of the U-Net Framework lies within the domain of image segmentation using U-Net. The framework's unique ability to localize features at multiple scales allows it to create precise delineation of object boundaries within an image. This makes it ideal for tasks that require high-precision segmentation, for instance, classifying different objects within an image, separating background from the foreground, or identifying specific regions or objects of interest in a larger image. It does this by applying a series of convolutional and pooling operations to the input image, extracting high-level features along the way. These extracted features are enlarged through a series of upsampling and concatenation operations to create a segmentation map the same size as the initial image. This capability sets U-Net apart from other image segmentation frameworks and explains its growing popularity in the fields of medical imaging and computer vision.
The Importance of Image Segmentation
In an era riddled with technological advancements, the importance of image segmentation in diverse industry applications is fast becoming prominent. The rise in demand can be traced back to its ability to enable machines to comprehend visual data more effectively. By fragmenting an image into smaller sub-segments, image segmentation simplifies the representation of an image making it more meaningful and easier to analyze. In a factory setting, for example, an administrative automated system could use image segmentation using U-Net to identify inconsistent components on an assembly line, highlighting faulty parts and preventing larger, costlier mechanical failures.
The striking significance of image segmentation can be realized by understanding how it powers computer vision, the primary driver of modern AI. Image segmentation using U-Net framework is a particularly notable breakthrough in this field. U-Net offers precise localization by using upsampled paths to prevent the loss of context, making it a highly adaptable tool for several different industries. For instance, in healthcare, a powerful image segmentation tool can aid early disease detection by helping radiologists identify nuances in medical scans that could signify the onset of a serious illness. Its usage is not limited to medicine; it extends to satellite imaging, self-driving vehicles, and more. Thus, a strong comprehension of image segmentation and its utility can open up a wide array of opportunities for more efficient visual data analysis and interpretation.
Understanding the Structure of U-Net Architecture

The U-Net architecture, an essential component in the realm of image segmentation using U-Net, is organized in a series of layers, each with a distinctive function. These layers work collectively to analyze and process input images. Essentially, each layer extracts a unique set of features from the input, progressing from abstract to detailed as we move deeper into the network. For instance, while one layer might identify edges, another layer may identify shapes formed from these edges, eventually piecing together the complete image representation.

The comprehensive structure of U-Net plays a pivotal role in improving image segmentation tasks. Layers close to the input focus on recognizing local features while layers further deep capture the contextual information. Subsequent to initial down-sampling layers, up-sampling layers in U-Net aim to restore the image’s resolution and spatial characteristics. Residual connections between these layers ensure the preservation of high-frequency details that could be lost during the network's down-sampling process. An analogy that helps clarify the working of U-Net would be 'a detective solving a crime scene.' The input image is the crime scene, and the U-Net layers represent steps in the detective's investigatory process. Initial layers (like the detective's primary analysis) identify basic details in the image, whereas deeper layers (akin to subsequent investigation) uncover more complex patterns and relationships. This staged segregation and combination of image features eventually lead to an exceptionally accurate image segmentation using U-Net.
Building the U-Net Model
Building the U-Net model for image segmentation involves understanding the composition and arrangement of layers within the structure. In essence, the U-Net model is comprised of various interconnected layers such as the convolutional layers, rectified linear unit (ReLU) layers, and the max pooling layers, among others. By leveraging high-level languages such as Python and machine learning libraries such as TensorFlow, we can easily structure and build our U-Net model.
The initial step begins with preparing the image data for segmentation. Simply put, we need to preprocess and format our shared, consistent images to allow them to be compatible with our U-Net framework. This might involve normalizing the images, resizing them, or augmenting them to increase the diversity of our dataset. On scripting out the model, it's best to focus on the layers and their connectivity. The unique feature of a U-Net model lies in its symmetric expansive path which enables precise localization. Thus, when writing this part of the code, it's crucial to ensure every transition, from the contraction path to the expanding path, is defined accurately in the U-Net model.

Once the structure of our U-Net model is built and defined, we then compile it by choosing an optimizer, a loss function, and metrics. The optimizer is vital for minimizing the loss during training, thus influencing the accuracy of the image segmentation. While there are various optimizers to choose from, Adam (Adaptive Moment Estimation) optimizer is commonly used in most U-Net applications due to its adaptive learning rates. As for the loss function, it depends on the specifics of the segmentation task, but a popular choice often is the binary cross-entropy function. Finishing up, the prepared image data is then introduced to the model for training. However, one must ensure to save the model after training. This will enable the reproduction of results or future tweaking without undergoing the training process once again. It's also important to keep monitoring the training progress – look out for signs of underfitting or overfitting, and make adjustments accordingly.
Implementing Image Segmentation using U-Net
Implementing image segmentation using U-Net can be approached systematically. The first step involves utilizing the trained U-Net model to interpret and segment new images. The model, once adeptly trained via a richly diverse dataset, is capable of providing precise predictions which translate into high-quality image segmentations. Although automated, these segmentations are graced with the kind of detail that simulates the human-eye’s detection and differentiation nuances. The produced segments and classifications from the model's output aren't the final step. To add polish and finesse, we need to take the process a step further. By implementing additional post-processing steps, we can refine the segmentation results. These steps may include morphological operations like dilation or erosion, or the use of a smoothing filter to refine the image's edges. These post-processing steps optimize the results derived from U-Net, providing greater accuracy and enhanced image detail.
While it's clear how advantageous image segmentation using U-Net can be, it's vital to understand its interpretation of predictions. Judicious execution of these post-processing steps ensures that the model's predictions closely mirror the intended segmentations. This procedure adds an additional layer of quality control, tweaking where necessary to ensure the resultant image segments are clear and accurate. Ultimately, this multi-step process ameliorates not just the precision but the practical utility of the U-Net framework in wide-ranging uses.
Optimizing the U-Net Model Performance
Optimization in image segmentation using U-Net is a multi-pronged endeavor encompassing techniques like dropout, batch normalization, hyperparameter tuning, early stopping, and model checkpointing that contributes to preventing overfitting and enhancing model performance. Dropout and batch normalization play a vital role in stalling overfitting challenges. They provide a mechanism that adds an element of randomness that discontinues the unnatural adaptation of the model to the training data, thereby improving its generalization capability.
In addition, a clear balance between model complexity and generalization is imperative. A complex model may provide an excellent fit to the training data, but fall short when it comes to unseen data, hence reducing predictive power. On the contrary, a too simple model might lack the capacity to learn critical features from the training dataset, causing underperformance during prediction. The ideal model strikes a balance between being too complex and too simple, the point where it achieves the lowest validation loss. Hyperparameter tuning is another essential process for optimizing a U-Net model performance. Fine-tuning parameters such as the learning rate, batch size, or epoch number can lead to substantial improvements in model's performance and effectiveness. For instance, adjusting the learning rate might help the model to converge faster towards the global minimum or avoid getting stuck in local minima. Tools like grid search or random search are excellent choices for facilitating hyperparameter tuning tasks.

Lastly, introducing early stopping and model checkpointing during training can immensely enhance model optimization, solving two essential challenges in the model training process. Early stopping techniques monitor model performance during training and halt the process once the performance starts deteriorating. On the other hand, model checkpointing saves the model at certain intervals or after achieving specific performance benchmarks. This way, it allows us to have a fallback plan by providing the ability to revert to a version of the model that had the best performance. In conclusion, a multitude of strategies is required to optimize image segmentation using a U-Net model, all aimed at enhancing model's performance, preventing overfitting, and improving model's generalization ability on unseen data.
How to Validate your U-Net Model
To begin validating your U-Net model, you should first undergo the process of acquiring and preparing your validation dataset. While similar to the process you would utilize for your training data, this dataset should be distinct and unseen by your model. This ensures a fair assessment of your model's ability to generalize its learning to new data, ultimately highlighting the effectiveness of image segmentation using U-Net models.

Additionally, a robust understanding of evaluation metrics is an essential part of validating models. Primarily, these include accuracy, precision, recall, and the F1-score. Accuracy provides a basic measure of the proportion of correct predictions made by your model. Precision refers to how many correctly predicted positives there were out of all positive predictions made. Recall, or sensitivity, measures how many of the actual positives were identified correctly. The F1-score conveys the balance between precision and recall, essentially providing an aggregate measure.

Furthermore, these metrics serve a critical function. They allow you to evaluate your model's performance in a structured and quantifiable manner, demonstrating the capabilities of U-Net framework in image segmentation tasks. These metrics can be calculated efficiently using built-in library functions, granting invaluable insights into your model's functioning. Interpreting validation results is another pivotal step. It can be a complex task, requiring careful consideration of the interplay between different metrics, as no single measure provides an all-encompassing view. A model with high accuracy may suffer from low precision, or vice versa. Hence, understanding these nuances is crucial for improving your model. Lastly, these validation results should not be seen as the end of the process, but rather as a constructive tool. If your model shows subpar performance, use these findings to guide your adjustments and improvements. Be it changing the model architecture or tweaking the hyperparameters, validation results should inform your path forward, leading to a robust and efficient implementation of image segmentation using U-Net.
Concrete Examples of Image Segmentation using U-Net
In the realm of medical imaging, image segmentation using U-Net plays an integral role. The advanced computational abilities of U-Net are harnessed to detect and segment tumors from MRI scans. This allows healthcare professionals to acquire clear and detailed visuals, aiding them in early detection and precise therapeutics. An entirely different application can be observed in the burgeoning field of autonomous vehicles. Self-driving cars make use of U-Net architecture for segmenting roads and other objects crucial for navigation. The segmented images create a parameter establishing the vehicle’s path while avoiding collision with other objects, primarily enhancing the safety and reliability of autonomous driving.

Furthermore, U-Net has extended its developments in satellite imaging processing. Here, image segmentation using U-Net is employed to identify features such as buildings, roads, and other landmarks from satellite images. The information captured is processed to create maps and geographical data sets with immense accuracy, significantly contributing to urban planning, environmental research, and more. The industrial sector is another field that immensely benefits from image segmentation using U-Net. For example, U-Net is employed to detect defects in manufactured products. By segmenting images of products, it swiftly distinguishes between defected and flawless parts. This novel approach has drastically improved the efficiency and scalability of defect detection processes, significantly increasing productivity and quality assurance in manufacturing industries.
Challenges in Image Segmentation Using U-Net
Working with image segmentation using U-Net presents a unique set of challenges. One of the most dominant concerns revolves around the limitations associated with the size and quality of training data. Sufficiently large and varied datasets are critical for this process as they inform, guide, and improve the predictive accuracy of the model. However, acquiring adequate and diverse enough data of good quality is often difficult and time-consuming. Furthermore, the quality of the output directly corresponds with the quality of the input images, making this a key challenge for developers.

Another prevalent challenge when using a U-Net framework is the difficulty in successfully segmenting images where the objects are similar in appearance. For example, differentiating various tissues in medical images or discerning between varying types of road surfaces in autonomous driving applications can get extremely tricky. This is because the U-Net model might not be able to distinguish subtle differences in pixel values, leading to less accurate segmentation results. Finally, the process of image segmentation using U-Net comes with a computational cost. The advanced functionalities of the U-Net model, which provide precise results, indeed require considerable computational resources. Given the depth of network layers plus the intricate learning process, U-Net can prove demanding on the memory capacity of the processing unit. This can limit its utility in situations where robust hardware support is not available, thereby making it a challenge to implement U-Net in real-world, low resource scenarios.
Solutions to Overcome these Challenges
To tackle the challenges associated with image segmentation using U-Net, a multitude of strategies holds promise. Data augmentation tops the list, enhancing both the diversity and quantity of the training input. By applying timely transformations, the model learns to identify and segment various structures, even under different conditions, building up a robust architecture.

Another major breakthrough is the application of transfer learning and leveraging pre-trained models, moderating the computational demands significantly. This approach allows the model to benefit from the features learned by pre-existing models on extensive datasets, thus reducing training time and computing resources significantly. Alongside, advanced tactics like multi-scale representation offer significant promise in managing complex segmentation tasks. In principle, it operates by applying the model to the image at various scales, thereby gaining more comprehensive and precise context for segmentation. As part of a similar effort, the deep supervision technique aims at improving the learning of the early layers by minimizing the loss at multiple stages of the model.
Conclusion: Bringing It All Together
Completing this walkthrough on image segmentation using U-Net emphasized the significance and versatile applications of this technique within various industry settings. We delved into the intricate facets of the U-Net structure, uncovering the importance of each layer in the training process and the correlation between model complexity and generalization. The aim was to understand how to expertly construct, train, and optimize a U-Net model utilizing Python and TensorFlow. Surmountable challenges such as data quality and computational resource requirements were discussed, paired with solutions like transfer learning and data augmentation to make the process more feasible. Venturing into image segmentation using U-Net will undoubtedly fortify your abilities in computer vision tasks and push the boundaries of what is possible in terms of machine understanding of visual data.